 迁址公告
迁址公告
 古东管家APP
古东管家APP
 关于我们
关于我们
如果你想第一时间看到我们的文章
就把☆星标☆点起来吧


来源 | 伯虎财经(bohuFN)
作者 | All too well

今年2月,当恒生科技指数还处在一路向南的惨淡当中时,有两个“小登”走出了不一样的行情。上市两个月的智谱从一月底的226.4港元每股一路飙升到发稿前的628港元每股;上市不过一个半月的MiniMax从一月底的473港元每股上涨到发稿前的880港元每股。
两家公司市值均一度跨过3000亿港元关口。
3000亿港元是什么概念?横向对比一下就很直观——当前B站总市值957.17 亿港元,京东市值约为3016.79亿港元。也就是说,这两家成立还尚不足十年的AI公司,市值已经悄然越过许多互联网巨头。
和“小登”在二级市场予取予求不同,大厂们正忙着让更多人用上AI。
今年春节,字节、阿里和腾讯纷纷取消了春节休假,严阵以待,应对用重金换来的AI需求。在各家的战报里,仅除夕当天,豆包 AI 互动总次数达到 19 亿次;阿里花费30亿元,让近 2 亿用户使用千问下单消费;腾讯用10亿红包,换来了1.14 亿的月活新高。
这是大厂们2026年的第一波交锋。如何撬动和发现更多的需求?如何先人一步的占据AI时代的入口?这是大厂们关心的问题。
无论是大厂们的撒币买用户,还是二级市场上的AI“小登”当道,都是AI时代里的不同切口。毫无疑问的是,AI应用已经开始深入融合我们的生活,它既站在港股AI“小登”的升浪中,也藏身在大厂的FOMO情绪里,催促后者把它推向每一个人。

2026,AI商业化元年?
MiniMax和智谱的狂飙之所以让不少人担忧,很大程度上是因为他们的市值无法适用于传统的估值模型。
即便是把它们放到AI企业的篮子里,也属于是被严重高估的。美国同行Anthropic 最新估值约 3800 亿美元,年化收入已经超过 20 亿美元,市销率大约 190 倍。而如果以MiniMax前九个月5344 万美元对应的3000亿港元营收来算,后者的市销率超过 700 倍。
但推动MiniMax和智谱这波上涨的重要原因是,它们的新模型证明了中国AI团队有能力用算法效率弥补硬件短板,做出让专业用户为之付费、好用的模型。
以智谱为例。
程序员一直是AI的重要付费群体,此前大火的vibe coding就是让AI作为产出工具来完成写代码的工作。但在全球权威编程基准测试里,闭源模型的领先一直很明显。
智谱新发布的GLM-5打破了这个惯例,从Artificial Analysis测试的结果来看,GLM-5直接跻身智能程度全球第4,编程能力全球第6,代理能力全球第3,紧追顶尖的闭源模型。而在AA-Omniscience幻觉率测试中,GLM-5把幻觉率压缩至34%。
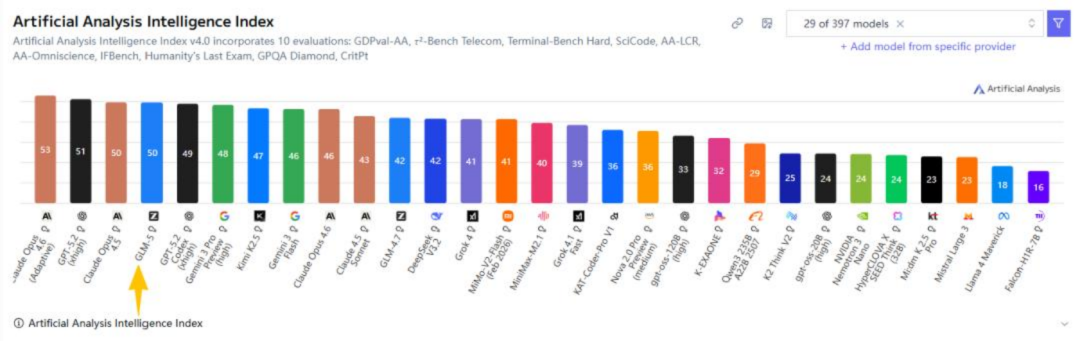
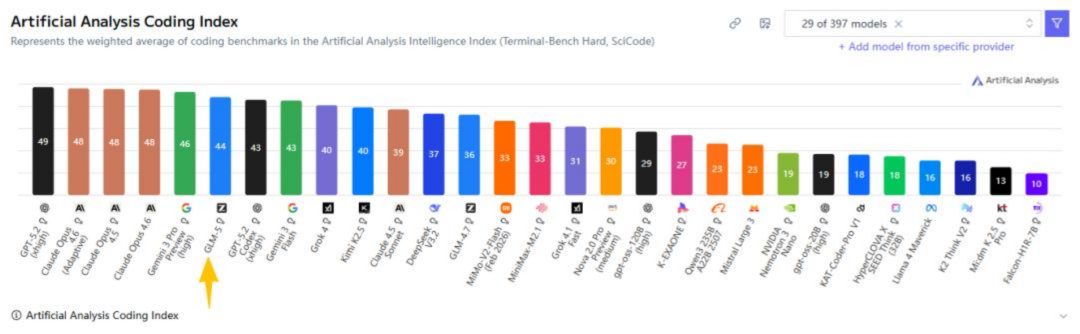
除了在推理、代码和自主能力上的全面升级,GLM-5还大幅降低了运行成本。GLM-5引入的深度稀疏注意力机制让它能够根据内容智能筛选出最重要的词,举个例子,同样是12.8万个词的长文本,GLM-5的计算量直接砍掉了一半到三分之二。因此,GLM-5的参数总量扩展到了7440亿,但每次实际激活运算的参数只有400亿。
新模型发布后,由于用户规模与调用量快速提升,智谱还官宣GLM Coding Plan价格上调30%以上。主打轻量化和效率的MiniMax M2.5在被以OpenClaw为代表的Agent需求推动下,只用了一个星期的时间,就成了OpenRouter上Tokens调用量的榜一。
不再追求模型参数,而是让用户真正用起来,这和过去我们熟悉的AI厂商开打价格战的竞争态势是截然不同的。
即便是仍然花大价钱买用户的大厂们,实际上竞争的也是好用。
晚点LatePost报道,2025 年初,字节跳动 CEO 梁汝波曾在集团全员会上说,豆包没显出 “越多人用越好用” 的互联网产品特性,他提出字节要追求智能上限。春节前,Doubao2.0升级,除夕当天,Qwen3.5上线。两者同样强调Agent执行能力,能办事,真有用。视频生成模型Seedance2.0发布后,游戏科学CEO、《黑神话:悟空》制作人冯骥更是发出了“AIGC的童年时代,结束了”的感叹。
和小登们不同的是,这些拥有庞大生态、版图从电商、生活服务蔓延到短视频、游戏乃至支付巨头们,还需要借由AI继续巩固自己的地位。
所以千问接入了淘宝闪购、支付宝、淘宝、飞猪、高德等阿里系应用,为了让千问的使用体验更好,阿里投入了大量资源,每周更新2-3 次,一些需求从设计到上线仅需 1-3 天。
无论是智谱和MiniMax的抢跑,还是大厂的红包大战,其实都在面向不同的人群,努力让AI真正被用起来。

繁荣背后的隐忧
OpenRouter数据显示,今年2月第一周处理的AI tokens达到13万亿,环比1月第一周接近翻倍。这和当下行业的Agent爆发式增长有很大关系。
在海外,OpenClaw作为一款开源的个人AI助手,能够在本地电脑或服务器上自主运行,并通过自然语言指令执行各种任务。它的爆火速度堪称史诗级,其在发布后的短短一周内就突破10 万颗星标,成为GitHub历史上增速最快、关注度最高的开源项目之一。
虽然当下处于墙内墙外两开花的状态,但AI应用还存在不少隐忧。
首先,高投入高亏损是行业常态,以智谱和MINIMAX为例。
2022—2024年、2025年上半年,智谱的营收分别为0.57亿元、1.25亿元、3.12亿元、1.91亿元,净利润分别为-1.43亿元、-7.88亿元、-29.56亿元、-23.51亿元,三年半亏损62.38亿元。
2022—2024年、2025年前三季度,MINIMAX营收分别为0、0.03亿美元、 0.31亿美元、0.53亿美元,分别实现净利润-0.74亿美元、-2.69亿美元、-4.65亿美元、-5.12亿美元,三年又三个季度合计亏损13.2亿美元。
亏损主要出在人力成本和算力成本。据海豚投研分析,两个公司员工整体都没超1000人,尤其是Minimax都不足400人;两家公司研发人员都接近75%,单人头月成本6.5-8.5万元人民币(不含期权激励),其中Minimax研发人员单人月成本是16万。
看着不低的人力成本,但和动不动上亿美金抢人大战的惨烈比起来,又不算离谱。真正的压力来自算力。
从两家公司披露的数据来看,单单模型训练相关的算力投入,就占到了总支出的 50% 以上,是绝对的大头,也是亏损的核心来源。
以 2023 年为例,研发一代模型的训练成本大约在四五千万美元之间。而当模型进入下一代,为了实现代际差异,无论是数据量、参数规模还是算力需求,往往都呈现指数级增长。模型升级一代,训练成本提高 3—5 倍几乎是常态。
也就是说,算力效率提升了,但算力总需求却在放大。
一方面,模型规模持续膨胀,多模态能力不断叠加;另一方面,Agent、编程助手等高频场景开始落地,调用次数迅速上升。在这种情况下,即便单次 token 成本快速下行,只要总调用量和模型复杂度同步飙升,企业最终要支付的算力总账单,反而可能越滚越大。
这也解释了,为什么推理成本明明在下降,公司烧钱却越来越厉害。
根据灼识咨询数据,行业平均推理成本已从2022年底每百万 token 约 20 美元降至 2024 年底不足 0.1 美元,未来仍可能继续下降。单次调用确实更便宜了。
与此同时,2024 年,MiniMax 与推理及训练相关的云计算成本合计约 1.67 亿美元,占营收比例达 545%。也就是说,每赚1块钱,要付出 5 块多的算力费用。智谱当年计算与算力服务费合计 15.83 亿元,占营收 506%。每进账 1 块钱,大约 5 块被算力吞掉。
而且这种趋势还愈演愈烈。智谱的算力服务费占研发开支比例,从 2022 年的 17.3%,一路爬升到 2025 年上半年的 71.8%;MiniMax 与训练相关的云计算开支占研发比例,也从 39.4% 提升至接近 80%。
这就意味着,目前的情况下,模型要优秀,训练成本就越高,收入似乎也跟不上更新迭代的速度,到底何时才会有个结果?
其次是监管和侵权风险。比如Seedance2.0不仅收到了来自版权方的律师函,还下线了争议极大的真人素材参考能力。
浪潮之下,毕其功于一役是不切实际的想法。AI的参与者们面临的是一场真实的商业战争,而刚刚过去的春节可能只不过是一道开胃前菜罢了。
参考来源:
1、至顶AI实验室:智谱GLM-5技术曝光,代码能力已经赶上Claude?
2、硅基星芒:智谱与Minimax交出“大招”之后,DeepSeek“平A”了一下
3、晚点AI:春节 AI 战役全记录:红包、模型与算力
4、字母AI:跟Claude掰腕子,智谱MiniMax双模齐发
5、海豚投研:深扒Minimax与智谱:大模型,一场算力强度与融资耐力的残酷绝杀?
6、极客公园:为什么所有人都觉得MiniMax、智谱「太贵了」?
7、厚雪研究:中国“大模型双雄”上市:研发支出70%-80%花在算力
文章封面首图及配图,版权归版权所有人所有。若版权者认为其作品不宜供大家浏览或不应无偿使用,请及时联系我们,本平台将立即更正。


Topic:你如何评价MiniMax和智谱的这波暴涨?
我们将挑选1位评论用心且点赞数较高的用户
送出一本《怒放》
找不到伯虎财经的文章?
如果你想第一时间看到我们的内容
就把☆星标☆点起来吧






让我知道你“在看”哟~
免责声明:所有平台仅提供服务对接功能,资讯信息、数据资料来源于第三方,其中发布的文章、视频、数据仅代表内容发布者个人的观点,并不代表泡财经平台的观点,不构成任何投资建议,仅供参考,用户需独立做出投资决策,自行承担因信赖或使用第三方信息而导致的任何损失。投资有风险,入市需谨慎。
请先登录后发表评论